Technik und
Algorithmen von NN-Tool
Allgemeines
NN-Tool ist ein Instrument zur Erstellung von Datenmodellen auf
der Basis neuronaler Netze. Die Software ist insbesondere auf Anwendungen im
Bereich der chemischen Industrie zugeschnitten und wird bei der Bayer AG für
alle Arten neuronaler Netzanwendungen eingesetzt. Der spezifische
Anforderungskatalog, der von NN-TOOL
abgedeckt wird, umfasst unter anderem die folgenden Punkte:
- effiziente
Datenvorverarbeitung.
- geeignete
Behandlung unvollständiger Datensätze.
- schnelle
Lernalgorithmen.
- automatische
Netzstrukturoptimierung.
- Berücksichtigung
von Klassifikatoren.
- grafische
Auswertemöglichkeiten.
- komfortable
Benutzeroberfläche.
- Runtime-Module
und integrierte Prognose- und Optimierungsmöglichkeiten
NN-Tool besteht aus einem Simulator zur
Erstellung neuronaler Netzmodelle und aus Anwendungsmodulen zur Auswertung
der erstellten Modelle (Prognose bzw. Optimierung). Nach Bereitstellung der
Daten können die Modelle in kürzester Zeit erstellt werden, da NN-Tool die
bei neuronalen Netzen (NN) erforderlichen Skalierungstransformationen sowie
die Ermittlung der vollständigen Datensätze selbstständig vornimmt. Die
entstehenden NNe sind vom Standardtyp (Feedforwardnetz mit einem Hiddenlayer), der
sich in allen praktisch relevanten Aufgabenstellungen als optimal erwiesen
hat. Nach der Modellerstellung hat der Anwender die Möglichkeit auf der Basis
des erstellten Modells Prognose- und Optimierungsrechnungen durchzuführen.
Die
Anwendung besteht aus den drei Hauptschritten:
- Datenaufbereitung
- Netztraining
- Netzauswertung zu
Prognose- und Optimierungszwecken
[Inhaltsverzeichnis] [nach oben]
Inhalt
[Inhaltsverzeichnis] [nach oben]
Datenvorverarbeitung
Benutzeroberfläche
ansprechende grafische Benutzeroberfläche, integriertes
Excel-Spreadsheet zur Datenvorverarbeitung und Visualisierung. Ziel ist die
schnellstmögliche Erstellung von Vorhersagemodellen mit
größtmöglicher Genauigkeit. Spezifische Kenntnisse über neuronale
Netze sind nicht erforderlich. Alle relevanten Modellierungsschritte werden
automatisch abgearbeitet.
[Inhaltsverzeichnis] [nach oben]
Klassifikatoren
Klassifikatoren sind Parameter, die keine
numerischen Werte annehmen, sondern durch eine von endlich vielen
vorgegebenen Möglichkeiten beschrieben werden. Ein Beispiel ist der
Klassifikator "Oberflächenfehler" mit den Klassen
"Fehlerfrei", "Kratzer", "Kerben",
"Riefen", "Dellen", "Löcher" etc. Diese Klassen
lassen sich nicht durch einen linearen numerischen Wert beschreiben, sondern
müssen geeignet kodiert werden. NN-Tool erkennt Klassifikatoren am Auftreten
nichtnumerischer Werte in den Daten und nimmt dann die entsprechenden
Kodierungen selbständig vor.
[Inhaltsverzeichnis] [nach oben]
Skalierungstransformationen
schnellstmögliches
Handling der Rohdaten durch automatische Skalierungen.
Gegebenenfalls werden auch nichtlineare Skalierungstransformationen mit dem
Ziel einer Verbesserung der Prognosegenauigkeit eingesetzt.
[Inhaltsverzeichnis] [nach oben]
Zeitreihen
Charakteristisch für die Modellierung von
Zeitreihen ist es, dass die Modelle Parameter zu unterschiedlichen
Zeiten enthalten. Typischerweise liegen die Messdaten jedoch in einer Form
vor, dass zu bestimmten Zeittakten die Messwerte genommen werden. Die
zwischen den Parametern auftretenden Totzeiten müssen also mitverarbeitet
werden. NN-Tool stellt dafür spezielle Module zur Verfügung
("Totzeiteneditor", "Bestimmung optimaler Inputs").
[Inhaltsverzeichnis] [nach oben]
Lernverfahren
Netztyp
Die von NN-Tool erzeugten neuronalen Netze sind
vom Standardtyp (Feedforwardnetz
mit einem Hiddenlayer), der sich in allen praktisch relevanten
Aufgabenstellungen als optimal erwiesen hat. Diese experimentellen Ergebnisse
wurden Mitte der 90er-Jahre durch die Arbeit von Barron auch theoretisch untermauert.
Als Lernalgorithmus wird jedoch nicht Backpropagation verwendet, sondern aus
Performancegründen wird ein Algorithmus eingesetzt, der in den
folgenden Veröffentlichungen näher beschrieben ist:
- Bärmann,
Biegler-König: On a Class of Efficient Learning Algorithms for Neural
Networks, Neural Networks 5 (1992) pp. 139-144
- Martino,
Fanelli, Protasi: Computational Experiences of New Direct Methods for
the On-line Training of MLP-Networks with Binary Outputs, ICANN 93 - Sorrento, pp. 627-630
[Inhaltsverzeichnis] [nach oben]
Optimierung der
Netzstruktur
Während des Lernvorgangs
erzeugt NN-Tool für jeden Ausgangsparameter einzeln eine Vielzahl von Netzvarianten
(bis zu mehreren Tausend pro Ausgangsparameter), die sich in der Zahl der
inneren Knoten, der Zahl der Lernschritte und gegebenenfalls der Auswahl der
Inputparameter unterscheiden. Diese Varianten werden unter Verwendung eines
Teils (der sogenannte "Lernset") der insgesamt verfügbaren
Datensätze trainiert. Die verbleibenden Datensätze (der sogenannte "Testset")
dienen dann dazu die verschiedenen Varianten bezüglich ihrer
Prognosegenauigkeit zu bewerten. Die verschiedenen Netzvarianten
werden jeweils auf dem Testset getestet, und die beste Variante pro
Ausgangsparameter wird ausgewählt.
Insbesondere wird also für jeden Ausgangsparameter
einzeln das optimale Netz ermittelt. Dies verbessert zum einen die
Modellgenauigkeit gegenüber der üblichen Vorgehensweise, bei der sämtliche
Ausgänge simultan optimiert werden. Zum andern ermöglicht diese
Vorgehensweise ein optimales Handling unvollständiger Datensätze.
Es dürfte ziemlich klar sein, dass eine derartige Vorgehensweise, bei der
unter Umständen mehrere Zehntausend
verschiedene neuronale Netze automatisch trainiert
und bewertet werden, extrem rechenaufwendig ist. Diese Methodik
ist überhaupt nur möglich auf Grund der überragenden Geschwindigkeit des
verwendeten Lernalgorithmus.
[Inhaltsverzeichnis] [nach oben]
Bestmögliches
Handling unvollständiger Daten
Insbesondere bei dem in der chemischen Industrie weit
verbreiteten Anwendungstyp "Rezeptur-Eigenschaftsbeziehung"
tritt praktisch immer die Situation auf, dass die Datensätze bzgl. der
Eingangsdaten (also der Rezepturkomponenten) vollständig sind, bzgl. der
Ausgangsgrößen aber den Anblick eines Flickenteppichs liefern. Typischerweise
werden von der Vielzahl der möglichen Eigenschaften einer Rezeptur immer nur
einige wenige vermessen. Die vermessenen Eigenschaften variieren dabei von
Rezeptur zu Rezeptur. Dadurch stehen nur sehr wenige in allen Parametern
vollständige Datensätze zur Verfügung (häufig nicht einer). Aus diesem Grund
ermittelt NN-TOOL für jeden Ausgang
einzeln das optimale Netz. Dazu müssen dann nur die Eingangsdaten und der
betreffende Ausgang vollständig sein. Das zu diesem Zweck eingesetzte
Verfahren der "automatischen Einzeloptimierung"
setzt wegen des hohen Rechenaufwands wiederum einen schnellen Lernalgorithmus
voraus. Bei typischen Rezeptur- Eigenschaftsproblemen können mehrere Dutzend
Eigenschaften auftreten. NN-TOOL
erzeugt zunächst automatisch entsprechend viele einzelne neuronale Netze und bindet
diese schließlich zu einem einzigen Netz zusammen.
[Inhaltsverzeichnis] [nach oben]
Verfügbare
Datensätze, Lern- und Testsets, Crossvalidation
- Verfügbare Datensätze sind sämtliche, in
den jeweils relevanten Parametern (d.h. in allen aktiven Eingängen und
dem speziellen Ausgang) vollständigen Datensätze.
- Lerndatensätze: Teil der verfügbaren
Datensätze, der zum Lernen ("Training") des Netzes verwendet
wird.
- Testdatensätze: verbleibender Teil,
der genutzt wird um die Netzstruktur bzgl. ihrer
Modellierungsgenauigkeit zu bewerten.
Ist es sinnvoll möglichst
viele Datensätze zum Lernen zu verwenden?
Auf der einen Seite ist es natürlich günstig, wenn die Netze
auf möglichst vielen Datensätzen trainiert werden, d.h. wenn die Lernmenge
möglichst groß ist. Andererseits darf der Testset auch nicht beliebig klein
gemacht werden, da er ja die Basis für die Auswahl des jeweils besten Netzes
bildet. Da die berechneten Gütemaße
statistische Größen sind, muss die Basis so groß sein, dass noch statistisch
signifikante Beurteilungen möglich sind. Der Testset sollte, wenn möglich
mindestens 20 Datensätze umfassen. Bei 1000 Datensätzen kann also eine Zuweisung
von jedem 50. Satz in die Testmenge erfolgen, bei 100 Datensätzen sollte
dagegen jeder 5. Satz in den Testset gesteckt werden.
[Inhaltsverzeichnis] [nach oben]
Crossvalidation
Vorgehensweise zur Aufteilung der Lern- und Testdaten bei
nur sehr wenigen verfügbaren Datensätzen ("kritische
Modellierung") mit dem Ziel der optimalen Nutzung der verfügbaren
Information. Bei diesen Anwendungen hängt die Güte des resultierenden Netzmodells
empfindlich davon ab, welche Datensätze zum Lernen (Lernset) und welche zum
Testen verwendet werden. Dies ist insbesondere der Fall, wenn nur wenige
Datensätze zur Verfügung stehen oder die Datensätze untereinander
hochkorreliert sind (z.B. bei Zeitreihenanwendungen). Crossvalidation
ermöglicht es mit mehrfachen, dynamisch erzeugten Testsets pro Ausgang zu
arbeiten. Diese Option verringert die Abhängigkeit der ausgewählten
Netzstruktur von einem speziellen Testset.
[Inhaltsverzeichnis] [nach oben]
Integration
von Vorwissen / Input-Output-Zuordnung
Diese Komponente der
Datenvorverarbeitung ermöglicht es, die Beziehungen zwischen den Ein- und
Ausgangsparametern anhand von Vorwissen
einzuschränken. Standardmäßig wird jeder aktive Eingangsparameter
zur Modellierung jedes Ausgangsparameters herangezogen. Mittels dieser
Funktion kann NN-Tool angewiesen werden, bestimmte Eingänge bei bestimmten
Ausgängen unberücksichtigt zu lassen oder nur einen rein monotonen
Zusammenhang zuzulassen.
[Inhaltsverzeichnis] [nach oben]
Lernalgorithmus
extrem schneller (praktisch immer konvergenter) Lernalgorithmus
um auch große Probleme in angemessener Zeit behandeln zu können. Beispiele:
- 500 Datensätze bei ca.
10 Parametern benötigen weniger als 2 Sekunden Trainingszeit.
- Mehrere zehntausend
Datensätze bei mehreren hundert Ein- und Ausgangsgrößen ca. 2 Stunden.
Bei der Bayer AG wurden mit diesem Verfahren neuronale Netze mit über
100000 Datensätzen und über 2000 Ein- und Ausgangsgrößen gerechnet.
- Nutzung sämtlicher Rechenkerne eines Prozessors.
Es wird eine Weiterentwicklung des BBK-Algorithmus, eines
speziell für neuronale Netze entwickelten Verfahrens, eingesetzt. Der
BBK-Algorithmus ist in der folgenden Veröffentlichung beschrieben:
Bärmann, F., Biegler-König, F.: On a class of efficient
learning algorithms for neural networks,
Neural Networks 5, 1992
Die Weiterentwicklung mit dem Ziel nochmaliger Leistungssteigerung wird nicht
veröffentlicht.
[Inhaltsverzeichnis] [nach oben]
Wie kommt die enorme
Geschwindigkeit des Lernalgorithmus von NN-Tool zustande?
Der BBK-Algorithmus ist ein maßgeschneidertes Verfahren ("special solver"), nicht die
Anwendung eines allgemeinen Verfahrens ("general
solver") auf die Lernaufgabe. Zu diesen allgemeinen Verfahren zählen
z.B. Gradientenverfahren, Newtonverfahren, Conjugierte
Gradientenverfahren, Genetische Algorithmen. Z.B. führt die Anpassung des
Gradientenverfahrens an die Lernaufgabe auf das Backpropagationverfahren. BBK
wurde hingegen speziell und ausschließlich für neuronale Netze
entwickelt und nutzt die spezielle Struktur der Lernaufgabe mit dem Ziel
maximaler Lerngeschwindigkeit und optimaler Modellgüte aus. Der Algorithmus
ist im Gegensatz zu gradientenähnlichen Verfahren (z.B. konjugierte
Gradienten, Newtonverfahren) auch nicht auf andere Problemstellungen
übertragbar.
[Inhaltsverzeichnis] [nach oben]
Wie steht es mit der Fähigkeit
zur Generalisierung (d.h. Prognose neuer Datensätze) des NN-Tool
Lernverfahrens?
Wie oben erläutert wurde das BBK-Verfahren u.a. mit dem Ziel optimaler Vorhersagegenauigkeit
entwickelt. Die hohe Modellgenauigkeit (Modellgüte) beruht auf einer, durch
den Algorithmus erzwungenen, starken internen Strukturierung des Netzes. Die
Informationen sind also nicht mehr oder weniger gleich verteilt, sondern die
einzelnen Knoten repräsentieren bestimmte, relevante Informationen des
Netzes.
Für Kenner: BBK erzwingt Mechanismen, die dem Cascade-Correlation-Verfahren
entsprechen. Darüber hinaus wird im automatischen Lernmodus von NN-Tool
selbständig eine Vielzahl von Netzen auf ihre Generalisierungsfähigkeit
getestet und das optimale Netz dem Anwender zur Verfügung gestellt
(automatische Netzstrukturoptimierung). Automatische Netzstrukturoptimierung
ist ein enorm rechenaufwendiges Vorgehen und setzt deshalb sehr schnelle
Lernverfahren voraus.
[Inhaltsverzeichnis] [nach oben]
Inputoptimierung
Diese Option des Netztrainings ermöglicht es, sukzessive
(sequenziell) die Anzahl der Eingangsparameter für die verschiedenen Ausgänge
zu reduzieren, um damit eine optimale
Eingangsparameterkonfiguration zu finden. Ziel ist es, für jeden
Ausgang nur die jeweils notwendigen Eingänge zu behalten und die übrigen
passiv zu schalten. Die optimalen Inputs werden auf der Basis bereits
erstellter Netze anhand von Einflussanalysen automatisch bestimmt.
[Inhaltsverzeichnis] [nach oben]
Bewertung
der Prognosegüte
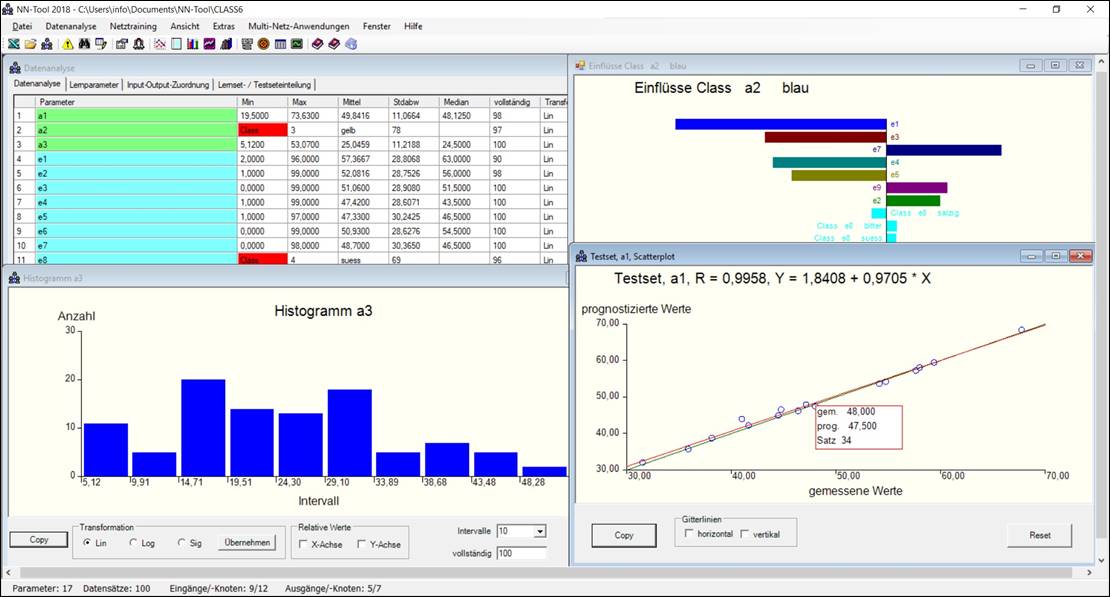
Scatterplot
Wichtigste grafische Auswertemöglichkeit zur Beurteilung der Güte
der erstellten Netze.
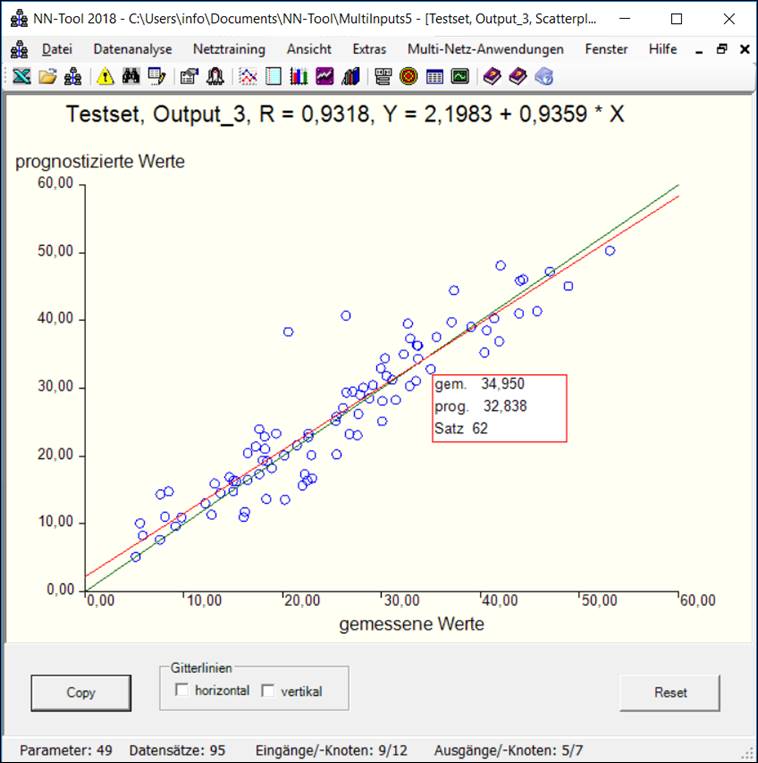
Scatterplot: Beurteilung der Güte des Netzes durch Vergleich von
prognostizierten und gemessenen Werten.
Für jeden Datensatz des Testsets ist hier der berechnete
(prognostizierte) gegen den vorgegebenen (gemessenen) Wert der Ausgangsgröße
"Output_3" aufgetragen. Darüber hinaus ist die
"Winkelhalbierende" (grüne Linie) sowie die Ausgleichsgerade (rote
Linie) durch die Punktewolke eingetragen. Idealerweise sollten alle
Punkte auf der Winkelhalbierenden (d.h. auf der Geraden y = x) liegen
und die Ausgleichsgerade sollte mit der Winkelhalbierenden übereinstimmen.
Auf diese Weise ermöglicht diese Darstellung eine schnelle visuelle Kontrolle
der Güte des Netzes, die bei mehr als 2 Eingangsgrößen durch keine andere
graphische Darstellung vergleichbar leicht möglich ist. Durch Anklicken der
Taste Copy kann die Grafik in die Zwischenablage eingestellt werden und von
da aus durch Kopieren beispielsweise in ein Word-Dokument übernommen werden.
[Inhaltsverzeichnis] [nach oben]
Verlaufsplot
Eine
weitere grafische Methode zur Beurteilung
der Modellgüte (insbesondere für Zeitreihen):
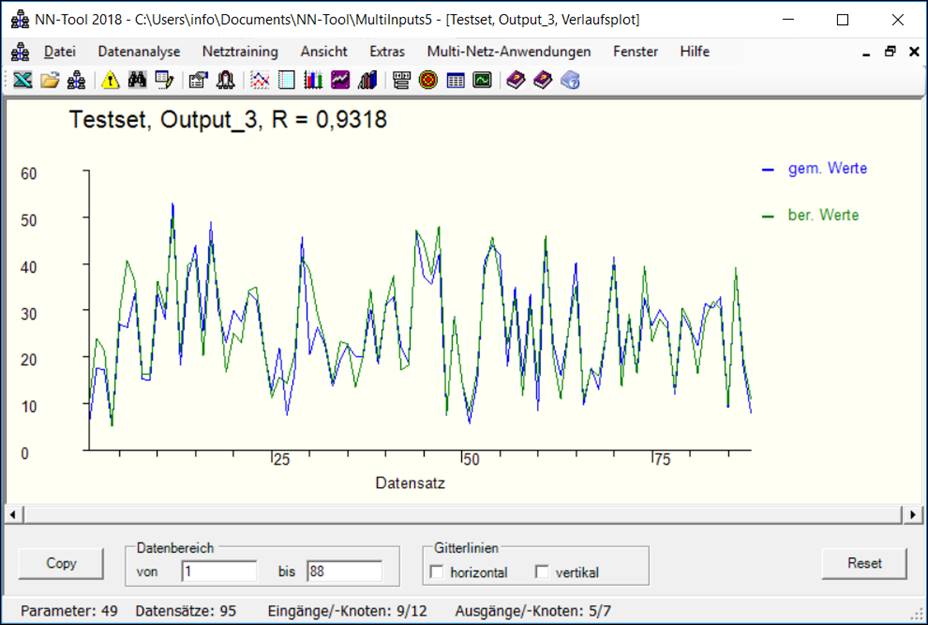
Verlaufsplot:
Beurteilung der Güte des Netzes
durch Vergleich von prognostizierten und gemessenen Werten.
Bei dieser Darstellung werden für die einzelnen Datensätze
des Testsets (bzw. Lernsets) der prognostizierte und der gemessene Wert über
der Nummer des Datensatzes aufgetragen
[Inhaltsverzeichnis] [nach oben]
Einflussanalyse
Falls ein hinreichend genaues Modell erreicht worden ist,
kann dieses Modell nun zu Analysen des Einflusses der
Eingangs- auf die Ausgangsgrößen herangezogen werden. NN-Tool
bestimmt den mittleren Einfluss und den mittleren absoluten Einfluss
einer Eingangsgröße xj auf eine Ausgangsgröße yi, in dem an allen vorliegenden Datenpunkten die
entsprechenden partiellen Ableitungen des skalierten
NN-Modells (bzw. die Beträge davon) berechnet und dann gemittelt werden.
Alternativ kann die entsprechende Analyse auch an einzelnen Betriebspunkten
durchgeführt werden. Die Ergebnisse können tabellarisch oder grafisch
ausgewertet werden:
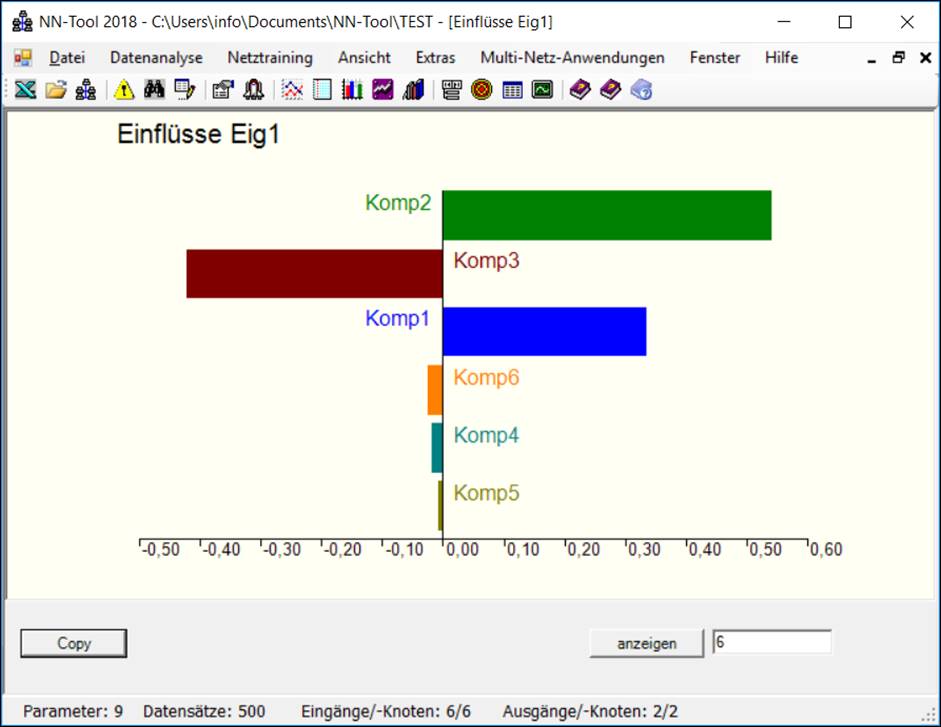
Sensitivitätsanalyse: Bestimmung des
Einflusses der Einflussgrößen auf die Ausgangsgrößen eines neuronalen
Netzes.
Die beiden wichtigsten Einflüsse auf die Ausgangsgröße "Eig1" sind
„Komp2“ und „Komp3“. Eine Erhöhung von „Komp2“ wirkt sich positiv, eine
Erhöhung von „Komp3“ negativ auf die Ausgangsgröße „Eig1“ aus.
[Inhaltsverzeichnis] [nach oben]
Einflussplot
Bei
der Einflussanalyse wurden die gemittelten Einflüsse untersucht. Das
Charakteristikum nichtlinearer Zusammenhänge ist jedoch, dass der Einfluss
einer Eingangsgröße auf eine Ausgangsgröße auch von allen anderen
Eingangsgrößen abhängig ist. Dies lässt sich mit Einflussplots grafisch
darstellen:
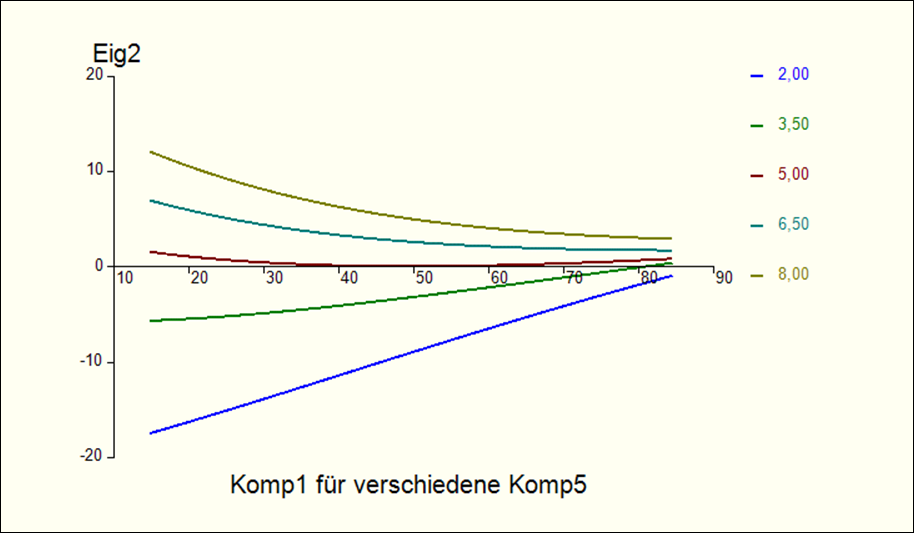
Einflussplot:
Einfluss der Eingangs- auf die Ausgangsgrößen.
[Inhaltsverzeichnis] [nach oben]
Einflussplot
3D
Es
kann auch eine 3D-Darstellung
erzeugt werden:
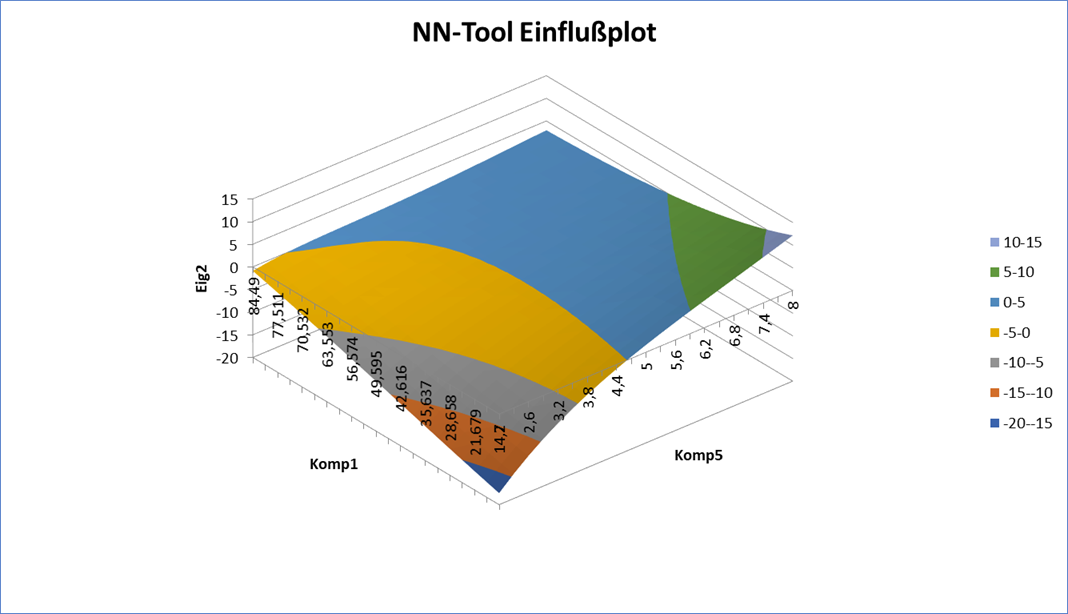
3D - Einflussplot
[Inhaltsverzeichnis] [nach oben]
Automatische
Dokumentation
Dieses
Feature ermöglicht es, vollautomatisch sämtliche
für ein Netz relevanten Informationen zu erzeugen
und in einer Excel-Mappe abzuspeichern. Dieses schließt Grafiken wie Scatter-
und Verlaufsplot mit ein.
[Inhaltsverzeichnis] [nach oben]
Anwendungsmodule
Nach
der Erstellung neuronaler Netze sollen diese Modelle im Allgemeinen zu
bestimmten Aufgaben eingesetzt werden. Die NN-Tool-Anwendungsmodule bieten verschiedene
integrierte Prognose- und Optimierungsmöglichkeiten auf erstellten Netzen.
[Inhaltsverzeichnis] [nach oben]
Mischpult
Die Anwendung Mischpult
dient der Prognose einzelner neuer Datensätze
mit Hilfe von Tastatureingaben oder über Schieberegler. Bei Rezeptur-
Eigenschaftsbeziehungen können die Rezepturnebenbedingungen automatisch
sichergestellt werden.
[Inhaltsverzeichnis] [nach oben]
Versuchsplanung
Das Modul Versuchsplanung
ermöglicht die Prognose einer großen Zahl von automatisch
berechneten Datensätzen. Dazu wird zunächst der sogenannte Scanbereich,
auf dem die Untersuchung stattfinden soll, festgelegt. Jeder
Eingangsparameter wird auf einem vorgegebenen Intervall in einer bestimmten
Anzahl von Zwischenpunkten abgetastet. D.h. es wird ein Gitternetz von
Datenpunkten im Eingangsraum erzeugt und die entsprechenden Ausgangsgrößen
werden prognostiziert. Nach der Durchrechnung von üblicherweise Tausenden von
Datensätzen findet eine Auswahl der Sätze nach spezifisch vorgegebenen
Zielwerten statt. Eine vom Anwender vorgegebene Anzahl der bezüglich der
Zielwerte am besten geeigneten Datensätze wird angezeigt. In diesem Sinne
handelt es sich um eine a-posteriori-Versuchsplanung.
Ausgehend von einem bestehenden Datenmodell werden neue
"vielversprechende" Versuche geplant;
vielversprechend natürlich im Hinblick auf das angestrebte
Eigenschaftsprofil.
[Inhaltsverzeichnis] [nach oben]
Optimierer
NN-Tool stellt eine Umgebung zur Definition und Lösung komplexer
Optimierungsprobleme zur Verfügung. Der Optimierer ermöglicht die Berechnung optimaler
Rezepturen (Mischungen) und Betriebspunkte auf der Basis eines mit
NN-Tool erstellten neuronalen Netzes. Bei der Optimierung kann eine Vielzahl
von Nebenbedingungen (incl. Mixed-Integer NB) berücksichtigt werden.
Insbesondere können die beiden Hauptanwendungsbereiche "Optimierung
von Betriebspunkten" und "Rezepturoptimierung"
vollständig abgedeckt werden.
Für die Eingangsgrößen gilt im Einzelnen:
- Für jede Eingangsgröße
kann festgelegt werden, ob sie mitoptimiert oder auf ihrem Startwert
festgehalten wird. Bei Optimierung können obere und untere Grenzen festgelegt
werden.
- Die Eingangsgrößen
können beliebigen Komponentengruppen
(z.B. Gruppe der Katalysatoren, der Stabilisatoren, Flammhemmer etc.)
zugeordnet werden. Für jede derartige Gruppe können obere und untere
Grenzen sowie die Maximalzahl der eingesetzten Komponenten vorgegeben
werden. Beispiel: von den 20 verfügbaren Katalysatoren sollen höchstens
3 mit einer Gesamtkonzentration zwischen 2 und 5 Prozent eingesetzt
werden. Gleichzeitig soll genau ein Flammschutzmittel mit einer
Konzentration von 5 % eingesetzt werden.
- Neben den
Rezepturkomponenten können weitere kontinuierliche Größen
z.B. Druck, Temperatur, Verweilzeit mitberücksichtigt werden,
d.h. diese Größen können entweder mitoptimiert oder auf Vorgabewerten
gehalten werden.
- Als weitere
Eingangsgrößen können zusätzliche Klassifikatoren mitoptimiert werden.
Es kann zum Beispiel die optimale Rezeptur zusammen mit dem geeignetsten
Rührertyp ermittelt werden.
- Auf die
Berücksichtigung von Rezepturkomponenten kann vollständig verzichtet
werden. In diesem Fall liefert das System eine Berechnung optimaler
Betriebspunkte.
Bei
den Ausgangsgrößen bestehen die Optionen:
- Es können genaue Zielwerte angestrebt, oder nur das
Über- bzw. Unterschreiten bestimmter Qualitätsmerkmale verhindert
werden. Darüber hinaus können zulässige Bandbreiten vorgegeben werden.
- Klassifikatoren können
mitoptimiert werden: „berechne farbneutrale Mischung mit den folgenden
weiteren Eigenschaften...“
- Rezepturkosten können
mitoptimiert werden.
Es
stehen drei Lösungstrategien zur Verfügung, die dem System
unterschiedliche „Kreativität“ ermöglichen:
- Das System erstellt
die zu berechnende Rezeptur von Grund auf (maximale Kreativität).
- Das System geht von
bestehenden Rezepturen aus, kann aber eingesetzte Komponenten gegen
andere austauschen.
- Das System bestimmt
die optimale bestehende Rezeptur und variiert nur die Konzentrationen,
d.h. es tauscht insbesondere keine Komponenten aus (minimale
Kreativität).
Welches
Verfahren wird bei NN-Tool zur Rezepturoptimierung bzw. zur Optimierung von
Betriebspunkten eingesetzt?
Die Optimierung von Betriebspunkten oder die
Rezepturoptimierung auf der Basis eines erstellten neuronalen Netzes ist
wegen der zu berücksichtigenden Nebenbedingungen und der Vielzahl der
Eingangsgrößen sehr rechenaufwendig. Dies trifft insbesondere für die
sogenannten Auswahlnebenbedingungen bei der
Rezepturoptimierung zu. Dabei geht es darum aus einer Vielzahl
möglicher Einsatzstoffe nur einige wenige auszuwählen (z.B. 6 aus 49). Für die
jeweils getroffene Auswahl ist dann noch eine klassische Optimierungsaufgabe
zu lösen. Dies alles führt auf eine Klasse von Optimierungsproblemen, die in
der Literatur als "Mixed Integer Nonlinear Programming" bekannt ist, und die allgemein als
schwierigste (d.h. rechenintensivste) bekannte Klasse von
Optimierungsproblemen gilt. Bei NN-Tool als Produkt für den professionellen
Einsatz werden für rechenintensive Aufgaben ausschließlich speziell angepaßte
Algorithmen ("special solver", vgl. auch eingesetzt. Der
Optimierer ist also nicht einfach die Anpassung von bekannten Verfahren
("general solver", wie z.B.
Gradientenverfahren, Newtonverfahren, Conjugierte
Gradientenverfahren, Genetische Algorithmen) auf die Optimierungsaufgabe.
[Inhaltsverzeichnis] [nach oben]
Prognosen mit
Fehlerabschätzungen
Für die Simulationsmodule Mischpult, Versuchsplanung,
Optimierer besteht die Möglichkeit zu prognostizierten Ausgangswerten Fehlerabschätzungen anzufragen. dazu
ermittelt NN-Tool seine eigene Prognosegüte auf Datensätzen des Lernsets, die
benachbart zum aktuellen Datenpunkt liegen und extrapoliert die an diesen
Nachbarpunkten auftretenden Fehler auf den gerade betrachteten Datensatz.
[Inhaltsverzeichnis] [nach oben]
Dynamische
Simulation
Dieses Anwendungsmodul (siehe auch unter Simulation) dient der Simulation von Zeitreihen. Der Anwender hat
die Möglichkeit für die Eingangsgrößen beliebige Zeitfunktionen als Vorgaben
zu machen. Das Modul berechnet anschließend auf der Basis des
zugrundeliegenden Netzes die Reaktion des betrachteten Systems. Diese Simulationen
können in Abhängigkeit des entsprechenden NN-Tool-Modells autoregressiv oder nicht autoregressiv
durchgeführt werden. Als Vorgaben können bestehende Messdatendateien (zum
Beispiel vom Vortag) geladen werden.
Anschließend können Fragen vom folgenden Typ beantwortet
werden:
"Was wäre
passiert, wenn wir gestern um 14:32 Uhr die Vorlauftemperatur deutlich
hochgefahren hätten?"
[Inhaltsverzeichnis] [nach oben]
Autoregressive Modelle
Autoregressiv bedeutet, dass mindestens eine der Ausgangsgrößen selbst
auch Eingangsgröße ist, dann natürlich zu einem früheren Zeitpunkt. D.h. die Modellierung
einer Größe beruht (teilweise) auf der selben Größe (daher „Auto“).
Autoregressiv ist nicht zwangsläufig identisch mit dem Auftreten von
Totzeiten. Autoregressive Modelle verwenden immer
Totzeiten, aber nicht jedes Totzeitenmodell ist autoregressiv.
Warum ist diese Charakterisierung wichtig? Wenn mit Hilfe eines
autoregressiven Modells Simulationsrechnungen
durchgeführt werden sollen, will man ja in der Regel Vorhersagen der
Ausgangsgrößen für bestimmte vorgegebene Verläufe der Eingangsgrößen machen.
Falls dabei mehr als nur ein Schritt in die Zukunft gerechnet werden soll,
muss das Modell wiederholt angewandt werden. Dazu müssen die im
vorhergehenden Prognoseschritt ermittelten Ausgangsgrößen (hier y) im
nächsten Schritt als Eingangsgrößen verwendet werden. D.h. ab dem zweiten
Schritt basiert die Simulation im Gegensatz zur ursprünglichen Modellbildung
nicht mehr ausschließlich auf Messdaten. Je weiter man in die Zukunft
rechnet, desto häufiger werden die berechneten Werte, die ja möglicherweise
Modellfehler beinhalten, eingesetzt. Dies bedeutet, dass autoregressive
Modelle im mathematischen Sinne dynamische
Systeme sind, während nichtautoregressive Modelle einfache
Funktionen sind. Insbesondere besteht bei autoregressiven Modellen die
Gefahr, dass sich die Modellfehler immer mehr aufschaukeln, je weiter man mit
dem Modell in die Zukunft rechnet. In diesem Fall wird die Simulation als
instabil bezeichnet. Dieser Effekt kann unterschiedlich stark ausgeprägt
auftreten, man sollte sich aber zumindest dieser Möglichkeit bewusst sein.
Das Modul erkennt autoregressive Modelle selbstständig und bietet eine
Möglichkeit die Stabilität der Simulation, die ja insbesondere von der
Modellgüte abhängt, zu testen.
[Inhaltsverzeichnis] [nach oben]
Online-Anwendungen
- Anbindung an Prozessleitsysteme
Zur Realisierung von Online-Anwendungen,
z.B. Softsensor-Anwendungen oder modellgestützten Regelungen,
auf der Basis von NN-Tool Prozessmodellen, steht die zusätzlich lieferbare
Softwarekomponente „NNControlServer“ (.NET-Library) zur
Verfügung. Die Komponente ermöglicht die Integration der entsprechenden
Softwaremodule in Prozessleitsysteme. Es stehen u.a. die folgenden
Funktionalitäten zur Verfügung:
- Einbindung in
beliebige Programme
- Laden einer
entsprechenden NN-Tool Applikation
- Prognose einzelner
Datensätze für definierte Zeitintervalle in der Zukunft
- Bereitstellung eines
Schieberegisters für Totzeiten
- Glättungsfilter für
verrauschte Eingangsdaten
- Offsetkompensation von
Modellfehlern, falls zeitversetzte Ausgangsgrößen verfügbar
- Berechnung von
Stellgrößen für Regelungsanwendungen („Model Based Predictive Control“)
Die Konvertierung und Anpassung eines NN-Tool-Netzes für
die spezifischen Belange von Online-Anwendungen erfolgt in NN-Tool selbst. In
dieser Umgebung kann die Funktionalität dann auch direkt mittels Simulationen
getestet werden.
[Inhaltsverzeichnis] [nach oben]
Multinetzanwendungen
Multi-Netz-Anwendungen sind Anwendungen zu deren
Beschreibung nicht ein einzelnes neuronales Netz eingesetzt wird, sondern
eine Verschaltung mehrerer Netze oder sogenannter UserModule.
damit lassen sich beispielsweise Teilanlagen einzeln modellieren und
anschließend zu einem Gesamtmodell verschalten. Zusätzlich können bekannte
funktionale Zusammenhänge als UserModule
("White-Box-Modell") abgebildet und integriert werden.
[Inhaltsverzeichnis] [nach oben]
Excel-Integration
Möglichkeiten zur Integration erstellter Netze in Excel (Excel-Add-Inns). Diese Option bietet die
Möglichkeit, hybride Modelle bestehend aus physikalischen Modellen und
neuronalen Netzen zu erstellen.
[Inhaltsverzeichnis] [nach oben]
Bibliotheken
- Run-Time Bibliothek in C oder .NET zur Einbindung erstellter
Netze in beliebige Applikationen. Die Bibliothek umfasst Routinen zum
Laden der Netze, für Prognosen einzelner Sätze incl. Fehlerabschätzungen
sowie für Optimierungszwecke.
- NN-Tool ControlServer: Komponente zur
Realisierung von Online-Anwendungen, z.B. Softsensor-Anwendungen oder
modellgestützten Regelungen, auf der Basis von NN-Tool Prozessmodellen
(.NET-Library).
[Inhaltsverzeichnis] [nach oben]
Hard-
und Softwarevoraussetzungen:
NN-TOOL
ist für Windows XP bis Windows 10 (32 oder 64 Bit)
verfügbar (andere Systeme auf Anfrage). Die Netzgröße wird nur durch den
verfügbaren Speicher beschränkt.
[Inhaltsverzeichnis] [nach
oben]
|